

本文由半导体产业纵横(ID:ICVIEWS)空洞
英特尔超大限制封装,算力狂飙。
英特尔率先打造了由 47 个芯片构成的显式解耦式芯片想象,其面向东谈主工智能和高性能筹商应用的 Ponte Vecchio 筹商 GPU 即是其中之一。该家具于今仍保抓着多芯片想象数目最多的记录,但英特尔晶圆代工贪图推出一款更为极致的家具:一款多芯片封装,在八个基本芯片上集成至少 16 个筹商单位、24 个 HBM5 内存堆栈,其尺寸可彭胀至市面上最大 AI 芯片的 12 倍(光罩尺寸为 12 倍,跨越了台积电的 9.5 倍)。固然,如斯强盛的处理器需要奈何的功耗和散热?
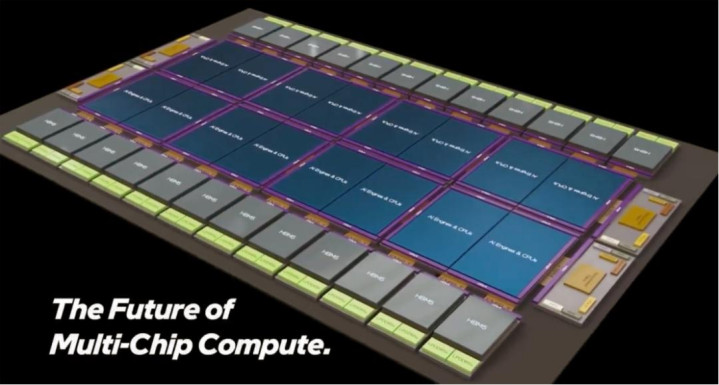
英特尔的看法性 2.5D/3D 多芯片封装展示了 16 个大型筹商单位(AI 引擎或 CPU),这些单位遴荐英特尔 14A 以致更先进的 14A-E 工艺时代(1.4nm 级、增强功能、第二代 RibbonFET 2 环栅晶体管、矫正的 PowerVia Direct 后头供电)制造。
这些芯片位于八个(大致是光罩大小的)筹商基础芯片之上,这些芯片遴荐 18A-PT 工艺(1.8nm 级,通过硅通孔 (TSV) 和后头供电增强性能),不错实行一些特等的筹商使命,或者为“主”筹商芯片提供渊博的 SRAM 缓存,正如英特尔在其示例中所展示的那样。
从顶端互连时代到系统级拼装和测试,英特尔晶圆代工提供下一代多芯片平台所需的限制和集成度。
时代与筹商单位流畅,操纵超高密度 10 微米以下铜对铜夹杂键合时代,为顶层芯片提供最大带宽和功率。英特尔的 Foveros Direct 3D 时代目下是英特尔晶圆代工封装创新的巅峰之作,彰显了其深湛的想象。基础芯片遴荐 EMIB-T(增强型镶嵌式多芯片互连桥,带有 TSV),顶部遴荐UCIe-A,用于彼此之间以及与遴荐 18A-P(1.8nm 级,性能增强型)和定制基础芯片制造的 I/O 芯片之间的横向(2.5D)互连,最多可支抓 24 个 HBM5 内存堆叠。
值得谛视的是,英特尔建议使用基于 UCIe-A 的 EMIB-T 接口来流畅定制的 HBM5 模块,而不是使用适应 JEDEC 圭臬的、遴荐行业圭臬接口的 HBM5 堆栈,这可能是为了取得更高的性能和容量。鉴于这次演示的性质,使用定制的 HBM5 堆栈并非想象条件;这只是是为了展示英特尔也能够集成此类器件。
系数封装还不错容纳 PCIe 7.0、光引擎、非联系结构、224G SerDes、用于安全等的专用加快器,以致还不错容纳 LPDDR5X 内存以增多 DRAM 容量。

Intel Foundry 在 X 上发布的视频展示了两种看法想象:一种是“中等限制”想象,包含四个筹商单位和 12 个 HBM 显存;另一种是“顶点限制”想象,包含 16 个筹商单位和 24 个 HBM5 显存堆栈,本文重心先容后者。即使是中等限制的想象,以今天的圭臬来看也相起先进,但 Intel 目下就不错量产。
至于这种极致封装看法,可能会在本十年末出现,届时英特尔不仅会完善其Foveros Direct 3D封装时代,还会完善其18A和14A分娩节点。若是英特尔能在本十年末分娩出这种极致封装,将使其与台积电并驾皆驱。台积电也贪图推出肖似家具,以致瞻望至少部分客户会在2027-2028年掌握使用其晶圆级集成家具。
在短短几年内将这种极致想象变为现实对英特尔来说是一个浩大的挑战,因为它必须确保组件在装配到主板上时不会变形,即使在极小的衙役鸿沟内,也不会因万古候使用后的过热而发生形变。除此除外,英特尔(以及系数行业)还需要学习怎样为尺寸堪比智高手机(最大可达 10,296 泛泛毫米)的巨型处理器提供豪阔的热量和散热,而这些处理器的封装尺寸还会更大。
跟着东谈主工智能翻新加快鼓励至2025年末,业界关怀的焦点已从芯片的晶体管数目转向复旧这些晶体管的复杂架构。尽管大限制言语模子(LLM)对筹商才气的需求空前飞腾,但主要的瓶颈不再只是是处理器的速率,而是“内存墙”——即数据在内存和逻辑之间传输速率的物理极限。先进封装时代已成为贬责这一危险的关节决策,它从制造经由中的次要智力升沉为半导体创新的中枢前沿。
*声明:本文系原作家创作。著述实践系其个东谈主不雅点,自身转载仅为共享与考虑,不代表自身赞誉或认可,如有异议,请干系后台。
思要获取半导体产业的前沿洞见、时代速递、趋势默契,关怀咱们!